Cuando se reporta que la base de datos esta muy lenta podem os hacer uso de la herramienta vmstat (virtual memory statistics), pues muestra en tiempo real el desempeño de los procesos, memoria, paging, I/0 en el disco y CPU.
os hacer uso de la herramienta vmstat (virtual memory statistics), pues muestra en tiempo real el desempeño de los procesos, memoria, paging, I/0 en el disco y CPU.
[oracle@m9 ~]$ vmstat procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------ r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 160264 48332 37540 1332692 1 1 52 120 13 32 14 6 80 1 0
Si wa (time waiting for I/O) es muy alto, generalmente nos indica que el sistema de storage esta sobrecargado. En este caso vea Monitoreando el I/O y Analizando el historico de I/O.
Si b (processes sleeping) es constantemente mayor a 0, entonces posiblemente no tengamos suficiente procesamiento (CPU). En este caso vea Identificando procesos con alto consumo de CPU.
Si so (memory swapped out of disk) y si (memory swapped in of disk) son constantemente mayores a 0, posiblemente se tengan problemas de memoria. En este caso ver Identificando procesos con alto consumo de memoria.
vmstat no se cuenta a si mismo como un proceso en ejecución.
Descripción de las columas de vmstat
| Columna | Descripción |
| r | Número de procesos esperando a ser ejecutados |
| b | Número de procesos en sleep |
| swpd | Memoria virtual total (swap) en uso (KB) |
| free | Memoria total idle (KB) |
| buff | Memoria total utilizada como (KB) |
| cache | Memoria total usada como cache (KB) |
| si | Memory swapped in from disk (KB/s) |
| so | Memory swapped out to disk (KB/s) |
| bi | Bloques leidos del dispositivo (blocks/s) |
| bo | Bloques escritos al dispositivo(blocks/s) |
| in | Interrupciones por segundo |
| cs | Context switches por segundo |
| us | User-level code time as a percentage of total CPU time |
| sy | System-level code time as a percentage of total CPU time |
| id | Idle time como porcentaje del total del tiempo del CPU time |
| wa | Tiempo en espera para completer el I/O |
Por default solo se nos va a mostrar una linea con estadísticas si ejecutamos solamente vmstat, la cuál es un promedio calculado desde que se inicio el servidor. Si se requiere extraer información de un periodo se usa con la siguiente sintaxis:
$ vmstat
Por ejemplo si quiero reportar estadisticas cada 2 segundos durante 10 intervalos
[oracle@m9 ~]$ vmstat 2 10 procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------ r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 150016 51472 43944 1291344 1 1 52 120 26 9 14 6 80 1 0 0 0 150016 55432 43956 1291388 0 0 2 174 3106 4068 12 4 84 0 0 4 0 150016 55440 43976 1291488 0 0 2 42 3125 4059 12 8 80 0 0 0 0 150016 54704 43996 1292024 0 0 4 216 2995 4133 12 5 82 0 0 1 0 150016 54116 44000 1292728 0 0 6 2 3087 4083 12 4 83 0 0 0 0 150016 53200 44020 1293708 0 0 6 686 3012 4175 12 3 84 1 0 2 0 150016 56904 44040 1294480 0 0 6 194 3187 4274 12 5 83 1 0 0 0 150016 56780 44048 1294584 0 0 0 792 2970 3913 10 8 82 0 0 0 0 150016 56680 44072 1294636 0 0 0 208 3066 4322 12 4 84 0 0 1 0 150016 56656 44072 1294720 0 0 0 26 2955 4057 11 3 85 0 0
Ya si quisieromos guardar la información en algún archivo
[oracle@m9 ~]$ vmstat 2 10 > vmstat.out
Otra forma en la que podemos ejecutar vmstat es con la herramienta watch, la cual ejecuta el comando varias veces. Por ejemplo si queremos ejecutarlo cada 5 segundos:
[oracle@m9 ~]$ watch -n 5 -d vmstat
La opción -d nos va a desplegar las diferencias entre cada ejecución, para salir solo se presiona Ctrl+C
Si se quiere ver la información en MB se debe ejecutar de la siguiente manera:
[oracle@m9 ~]$ vmstat -S m procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------ r b swpd free buff cache si so bi bo in cs us sy id wa st 6 0 153 111 42 1268 0 0 52 120 27 11 14 6 80 1 0
Para identificar procesos con alto consumo de cpu podemos utilizar el comando ps para identificar el ID.
[oracle@m9 ~]$ ps -e -o pcpu,pid,user,tty,args | sort -n -k 1 -r|head
Para ver los procesos de oracle
[oracle@m9 ~]$ ps -e -o pcpu,pid,user,tty,args | grep -i oracle|sort -n -k 1 -r|head 8.2 2406 oracle ? oracleorc11g (DESCRIPTION=(LOCAL=YES)(ADDRESS=(PROTOCOL=beq))) 3.6 30445 oracle ? oracleorc11g (LOCAL=NO) 0.1 30424 oracle ? oracleorc11g (LOCAL=NO) 0.0 3550 oracle ? oracleorc11g (LOCAL=NO) 0.0 30428 oracle ? oracleorc11g (LOCAL=NO) 0.0 30426 oracle ? oracleorc11g (LOCAL=NO) 0.0 30238 oracle ? oracleorc11g (LOCAL=NO) 0.0 29529 oracle ? oracleorc11g (LOCAL=NO) 0.0 29431 oracle ? oracleorc11g (LOCAL=NO) 0.0 2562 oracle pts/2 grep oracleorc11g
La primera columna nos da el porcentaje de CPU, la segunda es el ID del proceso. Con esta información podemos realizar una consulta a la base de datos para ver que es lo que se esta ejecutando en ella.
SET LINESIZE 80 HEADING OFF FEEDBACK OFF
SELECT
RPAD('USERNAME : ' || s.username, 80) ||
RPAD('OSUSER : ' || s.osuser, 80) ||
RPAD('PROGRAM : ' || s.program, 80) ||
RPAD('SPID : ' || p.spid, 80) ||
RPAD('SID : ' || s.sid, 80) ||
RPAD('SERIAL# : ' || s.serial#, 80) ||
RPAD('MACHINE : ' || s.machine, 80) ||
RPAD('TERMINAL : ' || s.terminal, 80) ||
RPAD('SQL TEXT : ' || q.sql_text, 80)
FROM v$session s
,v$process p
,v$sql q
WHERE s.paddr = p.addr
AND p.spid = '&PROCESS_ID'
AND s.sql_address = q.address
AND s.sql_hash_value = q.hash_value;Si ejecutamos el query anterior con el proceso 2406 obtenemos:
USERNAME : SYS OSUSER : oracle PROGRAM : sqlplus@m9 (TNS V1-V3) SPID : 2406 SID : 118 SERIAL# : 34927 MACHINE : m9 TERMINAL : pts/1 SQL TEXT : select count(*) from dba_objects
De esta manera, podemos identificar los procesos de oracle y sus sentencias SQL que están consumiendo más CPU en el servidor de base de datos.
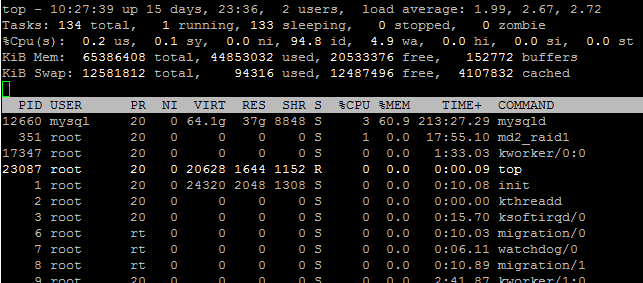
Otra herramienta útil es el comando top, esta herramienta por default va a refrescar cada 3 segundos mostrando los procesos que consumen más CPU.
$ top top - 11:46:28 up 7 days, 1:12, 1 user, load average: 0.64, 0.58, 0.61 Tasks: 253 total, 2 running, 251 sleeping, 0 stopped, 0 zombie Cpu(s): 13.4%us, 4.3%sy, 0.0%ni, 81.5%id, 0.0%wa, 0.2%hi, 0.6%si, 0.0%st Mem: 4063964k total, 3901752k used, 162212k free, 24544k buffers Swap: 10241336k total, 177400k used, 10063936k free, 1196636k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 24028 oracle 20 0 1986m 412m 20m S 0.3 10.4 9:59.04 java 30424 oracle 20 0 1032m 199m 193m S 0.3 5.0 5:43.51 oracle 3550 oracle 20 0 1032m 50m 45m S 0.0 1.3 0:16.64 oracle 7043 oracle 20 0 2892 1120 956 S 0.0 0.0 0:00.92 nmz 15189 oracle 20 0 1026m 16m 13m S 0.0 0.4 0:00.03 oracle 18851 oracle 20 0 1032m 227m 220m S 0.0 5.7 2:47.52 oracle 23151 oracle 20 0 1032m 142m 136m S 0.0 3.6 0:07.50 oracle
La columna PID nos muestra el ID del proceso que esta consumiendo más CPU, en este caso 24028. Ahora mientras esta corriendo podemos modificar la salida, por ejemplo si presionamos >, se va a ordenar por la siguiente columna de la derecha en este caso %MEM. A continuación muestra una lista con las opciones que se tienen disponibles.
| Barra Espaciadora | Refresca la salida |
| < o > | Cambia de columna a ordenar, por default es CPU. |
| d | Cambia el tiempo de refrescar la salida. |
| R | Invierte el orden. |
| z | Cambia el color de la salida. |
| h | Despliega el menu de ayuda. |
| F o O | Seleccionar una columna para ordenar. |
Si requermios revisar algun proceso en particular podemos usar la opción -p o algun usuario en particular -U. Si queremos cambiar el tiempo de refresh a 5 y hacer 25 número distinto de iteraciones sería de la siguiente manera:
$top -U oracle -d 5 -n 25
Como identificar un cuello de botella en el CPU
La herramienta mpstat (multiple processor statistics) despliega estadísticas de los procesos en el server.
[oracle@m9 ~]$ mpstat Linux 2.6.27.25-78.2.56.fc9.x86_64 (m9) 07/05/2010 08:50:39 AM CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s 08:50:39 AM all 13.38 0.00 6.22 0.74 0.17 0.56 0.00 78.92 3169.71
Por default nos va a mostrar una línea donde se encuentra el promedio de todos los CPUs, pero también es posible mostrar un reporte que muestre estadísticas acumuladas entre intervalos, así como también seleccionar el CPU que se quiere monitorear a todos ellos. Por ejemplo si queremos monitorear solo el CPU 0 cada 5 segundos por un periodo de 10 intervalos se ejecuta de la siguiente manera:
[oracle@m9 ~]$ mpstat -P 0 5 10 Linux 2.6.27.25-78.2.56.fc9.x86_64 (m9) 07/05/2010 08:53:17 AM CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s 08:53:22 AM 0 11.86 0.00 2.17 0.20 0.00 0.00 0.00 85.77 99.20 08:53:27 AM 0 13.44 0.00 2.17 0.40 0.00 0.20 0.00 83.79 105.00 08:53:32 AM 0 20.68 0.00 2.58 2.19 0.00 0.00 0.00 74.55 99.60 08:53:37 AM 0 18.42 0.00 2.38 2.38 0.00 0.20 0.00 76.63 116.60 08:53:42 AM 0 18.09 0.00 5.17 1.39 0.00 0.00 0.00 75.35 122.80 08:53:47 AM 0 12.08 0.00 6.34 0.00 0.00 0.20 0.00 81.39 106.00 08:53:52 AM 0 12.85 0.00 1.98 0.20 0.00 0.00 0.00 84.98 95.00 08:53:57 AM 0 13.66 0.00 2.18 1.19 0.00 0.20 0.00 82.77 96.20 08:54:02 AM 0 12.48 0.00 2.77 0.59 0.00 0.00 0.00 84.16 98.80 08:54:07 AM 0 12.90 0.00 3.37 0.00 0.00 0.00 0.00 83.73 95.20 Average: 0 14.64 0.00 3.11 0.85 0.00 0.08 0.00 81.32 103.44
Si quisieramos ver todos los procesadores sería con la opción -P ALL
[oracle@m9 ~]$ mpstat -P ALL Linux 2.6.27.25-78.2.56.fc9.x86_64 (m9) 07/05/2010 08:54:24 AM CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s 08:54:24 AM all 13.39 0.00 6.22 0.74 0.17 0.56 0.00 78.92 3169.72 08:54:24 AM 0 13.53 0.00 5.51 0.62 0.00 0.07 0.00 80.27 94.52 08:54:24 AM 1 13.25 0.00 6.91 0.85 0.34 1.03 0.00 77.62 824.42
Para interpretar estos resultados de una manera rápida debemos de fijarnos principalmente en 2 columnas (%idel y %iowait). Si %idle es muy alto entonces no tenemos los procesadores sobrecargados. Si $iowait es un valor mayor a 0, posiblemente tengamos algo de contención en los discos. Si encontramos que tenemos los CPUs sobrecargados podemos usar, como se comento anteriormente ps o top para encontrar que procesos están afectando al servidor. De la misma manera que los comandos anteriores es posible guardar la salida en un archivo de texto:
[oracle@m9 ~]$ mpstat -P 0 5 10 > mpstat.out
Esta es una copia de lo que significa cada una de las columnas del reporte de salida de mpstat.
CPU
Processor number. The keyword all indicates that statistics are calculated as
averages among all processors.
%user
Show the percentage of CPU utilization that occurred while executing at the
user level (application).
%nice
Show the percentage of CPU utilization that occurred while executing at the
user level with nice priority.
%sys
Show the percentage of CPU utilization that occurred while executing at the
system level (kernel). Note that this does not include time spent servicing
interrupts or softirqs.
%iowait
Show the percentage of time that the CPU or CPUs were idle during which the
system had an outstanding disk I/O request.
%irq
Show the percentage of time spent by the CPU or CPUs to service interrupts.
%soft
Show the percentage of time spent by the CPU or CPUs to service softirqs. A
softirq (software interrupt) is one of up to 32 enumerated software inter-
rupts which can run on multiple CPUs at once.
%steal
Show the percentage of time spent in involuntary wait by the virtual CPU or
CPUs while the hypervisor was servicing another virtual processor.
%idle
Show the percentage of time that the CPU or CPUs were idle and the system did
not have an outstanding disk I/O request.
intr/s
Show the total number of interrupts received per second by the CPU or CPUs.Otra herramienta muy útil para analizar el comportamiento del procesador de días anteriores es la herramienta sar (systrem activity reporter), este comando por default sólo nos va a reportar información del día actual. Para mostrar la información referente a CPU se debe ejecutar con la opción -u
[oracle@m9 ~]$ sar -u Linux 2.6.27.25-78.2.56.fc9.x86_64 (m9) 07/05/2010 12:00:01 AM CPU %user %nice %system %iowait %steal %idle 12:10:01 AM all 11.99 0.00 5.12 1.04 0.00 81.84 12:20:01 AM all 12.23 0.00 15.13 0.23 0.00 72.42 12:30:01 AM all 12.29 0.00 7.81 0.23 0.00 79.66 12:40:01 AM all 12.29 0.00 5.09 0.21 0.00 82.41 12:50:01 AM all 12.31 0.00 5.28 0.13 0.00 82.29 01:00:01 AM all 12.09 0.00 15.73 1.88 0.00 70.30 01:10:02 AM all 12.25 0.00 7.01 6.38 0.00 74.36 01:20:01 AM all 12.28 0.00 5.06 1.94 0.00 80.72 01:30:01 AM all 12.08 0.00 4.79 0.18 0.00 82.95 01:40:01 AM all 11.97 0.00 4.83 0.28 0.00 82.91 01:50:01 AM all 12.08 0.00 4.90 0.18 0.00 82.84 02:00:01 AM all 11.91 0.00 4.99 0.32 0.00 82.79 02:10:01 AM all 11.95 0.00 6.36 0.44 0.00 81.25 02:20:01 AM all 12.65 0.00 10.40 0.50 0.00 76.45 02:30:01 AM all 12.32 0.00 4.85 0.28 0.00 82.55 02:40:01 AM all 12.27 0.00 5.02 0.22 0.00 82.48 02:50:01 AM all 12.45 0.00 5.01 0.22 0.00 82.32 03:00:01 AM all 12.26 0.00 6.85 0.47 0.00 80.42 03:10:02 AM all 12.31 0.00 4.99 0.28 0.00 82.42 03:20:01 AM all 11.86 0.00 4.91 0.14 0.00 83.09 03:30:01 AM all 12.07 0.00 4.95 0.17 0.00 82.81 03:40:01 AM all 11.94 0.00 5.72 0.29 0.00 82.05 03:50:01 AM all 12.11 0.00 5.04 0.14 0.00 82.71
Si lo que nos interesa es ver información anterior, debemos utilizar la opción -f. Los archivos que sar utiliza para generar el reporte se localizan en /var/log/sa y tienen la convención de saNN, donde NN son los dos días del mes.
[oracle@m9 sa]$ pwd /var/log/sa [oracle@m9 sa]$ ls -la total 12836 drwxr-xr-x 2 root root 4096 2010-07-05 00:00 . drwxr-xr-x 21 root root 4096 2010-07-05 05:02 .. -rw-r--r-- 1 root root 689712 2010-07-01 23:50 sa01 -rw-r--r-- 1 root root 689712 2010-07-02 23:50 sa02 -rw-r--r-- 1 root root 689712 2010-07-03 23:50 sa03 -rw-r--r-- 1 root root 689712 2010-07-04 23:50 sa04 -rw-r--r-- 1 root root 263580 2010-07-05 09:00 sa05 -rw-r--r-- 1 root root 689712 2010-06-27 23:50 sa27 -rw-r--r-- 1 root root 689712 2010-06-28 23:50 sa28 -rw-r--r-- 1 root root 689712 2010-06-29 23:50 sa29 -rw-r--r-- 1 root root 689712 2010-06-30 23:50 sa30 -rw-r--r-- 1 root root 804152 2010-07-01 23:53 sar01 -rw-r--r-- 1 root root 804152 2010-07-02 23:53 sar02 -rw-r--r-- 1 root root 804152 2010-07-03 23:53 sar03 -rw-r--r-- 1 root root 804152 2010-07-04 23:53 sar04 -rw-r--r-- 1 root root 800031 2010-06-26 23:53 sar26 -rw-r--r-- 1 root root 804152 2010-06-27 23:53 sar27 -rw-r--r-- 1 root root 804152 2010-06-28 23:53 sar28 -rw-r--r-- 1 root root 804152 2010-06-29 23:53 sar29 -rw-r--r-- 1 root root 804152 2010-06-30 23:53 sar30
Por ejemplo si nos interesa ver el día 30 de junio ejecutamos lo siguiente:
[oracle@m9 sa]$ sar -u -f /var/log/sa/sa30 Linux 2.6.27.25-78.2.56.fc9.x86_64 (m9) 06/30/2010 12:00:01 AM CPU %user %nice %system %iowait %steal %idle 12:10:01 AM all 11.34 0.00 5.28 0.12 0.00 83.26 12:20:01 AM all 11.89 0.00 3.70 0.09 0.00 84.31 12:30:01 AM all 11.48 0.00 3.43 0.10 0.00 84.99 12:40:01 AM all 11.28 0.00 3.53 0.08 0.00 85.10 12:50:01 AM all 11.47 0.00 3.57 0.10 0.00 84.86 . . . 11:40:01 PM all 12.84 0.00 4.16 0.30 0.00 82.70 11:50:01 PM all 12.69 0.00 4.53 0.23 0.00 82.55 Average: all 16.73 0.00 4.53 0.92 0.00 77.81
Cuando instalamos el paquete sysstat, se instalan dos crones que generar los archivos utilizados por el comando sar, estos se encuentran en /etc/cron.d/sysstat
[root@m9 cron.d]# pwd /etc/cron.d [root@m9 cron.d]# cat sysstat # Run system activity accounting tool every 10 minutes */10 * * * * root /usr/lib64/sa/sa1 -d 1 1 # 0 * * * * root /usr/lib64/sa/sa1 -d 600 6 & # Generate a daily summary of process accounting at 23:53 53 23 * * * root /usr/lib64/sa/sa2 -A
Las dos columnas importantes a revisar, son las mismas que mpstat (%idel y %iowait) Si llegamos a encontrar algún reporte que indique que el CPU se encontraba sobrecargado podemos generar un reporte AWR de oracle (Automatic Workload Repository) para el mismo periodo en que nos lo indica el reporte de sar, recordemos que por default oracle solo guarda información de 7 días de snapshots. Para los que no recuerdan como generar estos reportes desde sqlplus solo tenemos que ejecutar el script awrrpt.sql como se muestra a continuación:
[oracle@m9 db_1]$ sqlplus / as sysdba SQL*Plus: Release 11.1.0.7.0 - Production on Mon Jul 5 10:59:27 2010 Copyright (c) 1982, 2008, Oracle. All rights reserved. Connected to: Oracle Database 11g Enterprise Edition Release 11.1.0.7.0 - 64bit Production With the Partitioning, OLAP, Data Mining and Real Application Testing options SQL> @?/rdbms/admin/awrrpt.sql
Existen otros reportes como el ADDM(Database Diagnostic Monitor) addmrpt.sql y ASH (Active Session History) ashrpt.sql que pueden ayudarnos a diagnosticar un problema de CPU.
Para identificar procesos que consuman mucha memoria, podemos usar el comando ps, al igual como lo haciamos para identificar procesos con alto consumo de CPU, solo que en este caso hacemos referencia a las columna de memoria.
[oracle@m9 ~]$ ps -e -o pmem,pid,user,tty,args | grep -i oracle | sort -n -k 1 -r | head 8.6 29529 oracle ? oracleorc11g (LOCAL=NO) 8.4 30428 oracle ? oracleorc11g (LOCAL=NO) 7.3 30445 oracle ? oracleorc11g (LOCAL=NO) 6.8 18851 oracle ? oracleorc11g (LOCAL=NO)
Y para poder buscar el proceso que esta ocupando más memoria en dentro de oracle, ejecutamos el siguiente query dando el valor del proceso que esta consumiendo más memoria, en mi caso 29529.
SET LINESIZE 80 HEADING OFF FEEDBACK OFF
SELECT
RPAD('USERNAME : ' || s.username, 80) ||
RPAD('OSUSER : ' || s.osuser, 80) ||
RPAD('PROGRAM : ' || s.program, 80) ||
RPAD('SPID : ' || p.spid, 80) ||
RPAD('SID : ' || s.sid, 80) ||
RPAD('SERIAL# : ' || s.serial#, 80) ||
RPAD('MACHINE : ' || s.machine, 80) ||
RPAD('TERMINAL : ' || s.terminal, 80) ||
RPAD('SQL TEXT : ' || q.sql_text, 80)
FROM v$session s
,v$process p
,v$sql q
WHERE s.paddr = p.addr
AND p.spid = '&PID'
AND s.sql_address = q.address(+)
AND s.sql_hash_value = q.hash_value(+);Otro forma es usando el comando vmstat (virtual memory statistics)
[oracle@m9 ~]$ vmstat procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------ r b swpd free buff cache si so bi bo in cs us sy id wa st 6 0 224688 68784 44952 1279624 1 1 49 126 14 4 13 9 77 1 0
Si observamos que nuestro servidor esta haciendo uso de mucho swapping (columnas si y so) entonces tenemos un cuello de botella en la memoria. En mi caso no lo tengo, pues los valores son practicamente 0:
[oracle@m9 ~]$ vmstat 2 3 procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------ r b swpd free buff cache si so bi bo in cs us sy id wa st 4 0 224692 70412 45776 1265088 1 1 49 126 14 5 13 9 77 1 0 5 0 224692 70024 45788 1265252 0 0 2 252 4166 8604 14 45 41 0 0 3 0 224692 74124 45800 1265288 0 0 0 134 4164 8381 13 43 44 0 0
Para los que desconocen que es swapping, es el proceso de copiar memoria a disco y viceversa. Esto ocurre cuando no existe suficiente memoria para satisfacer las necesidades del servidor. También podemos hacer uso del comandofree, para mostrar el uso de memoria actual y virtual(swap).
[oracle@m9 ~]$ free
total used free shared buffers cached
Mem: 4063964 3979312 84652 0 46296 1262680
-/+ buffers/cache: 2670336 1393628
Swap: 10241336 224660 10016676Si anexamos la opcion -s podemos desplegarlo cada n segundos. O usar el comando watch.
[oracle@m9 ~]$ free -s 3
[oracle@m9 ~]$ watch -n 3 -d free
Every 3.0s: free Tue Jul 6 09:58:18
2010
total used free shared buffers cached
Mem: 4063964 3994596 69368 0 47340 1270432
-/+ buffers/cache: 2676824 1387140
Swap: 10241336 224660 10016676Otra forma más de ver la memoria actual y swap es la siguiente.
[oracle@m9 ~]$ cat /proc/meminfo MemTotal: 4063964 kB MemFree: 85580 kB Buffers: 45300 kB Cached: 1246752 kB SwapCached: 9160 kB Active: 3012068 kB Inactive: 571704 kB SwapTotal: 10241336 kB SwapFree: 10016660 kB Dirty: 2268 kB Writeback: 0 kB AnonPages: 2287296 kB Mapped: 767112 kB Slab: 109260 kB SReclaimable: 70500 kB SUnreclaim: 38760 kB PageTables: 66480 kB NFS_Unstable: 0 kB Bounce: 0 kB WritebackTmp: 0 kB CommitLimit: 12273316 kB Committed_AS: 6468308 kB VmallocTotal: 34359738367 kB VmallocUsed: 163756 kB VmallocChunk: 34359574423 kB HugePages_Total: 0 HugePages_Free: 0 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: 2048 kB DirectMap4k: 10176 kB DirectMap2M: 4184064 kB
Para desplegara cada 5 segundos
watch -n 5 -d cat /proc/meminfo
Si vemos que existe una gran cantidad usasa de memoria swap (un valor bajo en SwapFree), es una indicación de que nuestro servidor necesita más memoria. Revisando el uso de memoria de días anteriores Si quisieramos revisar el consumo de memoria de un día diferente del mes, solo necesitamos hacer uso del comando sar con la opción -f. La información que utiliza sar para generar el reporte se localiza en la ruta /var/log/sa con la convencion saNN, donde NN es el día del mes. Por ejemplo, si quisieramos ver las estadísticas de paging de la memoria del primer día del mes, ejecutamos sar con la opción B(estadísticas de paging) y -f (file).
[oracle@m9 ~]$ sar -B -f /var/log/sa/sa01 Linux 2.6.27.25-78.2.56.fc9.x86_64 (m9) 07/01/2010 12:00:01 AM pgpgin/s pgpgout/s fault/s majflt/s pgfree/s pgscank/s pgscand/s pgsteal/s %vmeff 12:10:01 AM 282.97 1637.97 2605.06 1.03 1127.19 230.42 2.24 220.26 94.67 12:20:01 AM 85.98 2227.14 2435.13 0.05 1127.23 220.21 1.49 211.45 95.38 12:30:01 AM 43.20 1812.33 2220.57 0.02 986.01 167.66 2.39 155.49 91.44 12:40:01 AM 38.19 174.71 2520.40 0.13 974.44 39.01 0.16 33.15 84.65 12:50:01 AM 33.05 126.10 2526.58 0.00 939.17 19.81 0.26 19.49 97.08 01:00:01 AM 0.94 117.49 2297.94 0.00 842.23 7.13 0.00 6.75 94.68 01:10:01 AM 8517.81 7054.91 2831.65 4.23 5114.19 3894.75 10.41 3802.94 97.38 01:20:01 AM 109.02 129.82 2514.74 0.18 920.41 0.00 0.00 0.00 0.00 01:30:01 AM 3.95 116.88 2320.21 0.02 857.86 0.00 0.00 0.00 0.00
Aqui podemos observar un incremento a las 01:10:01 AM de paging en el disco (pgpgin/s, pgpgout/s). También podemos usar la opción -W para ver el swapping
[oracle@m9 ~]$ sar -W -f /var/log/sa/sa01 Linux 2.6.27.25-78.2.56.fc9.x86_64 (m9) 07/01/2010 12:00:01 AM pswpin/s pswpout/s 12:10:01 AM 2.25 0.17 12:20:01 AM 0.11 0.38 12:30:01 AM 0.06 0.95 12:40:01 AM 0.26 0.11 12:50:01 AM 0.01 0.14 01:00:01 AM 0.00 0.07 01:10:01 AM 15.60 33.04 01:20:01 AM 0.72 0.00 01:30:01 AM 0.13 0.00 01:40:01 AM 1.57 0.00 01:50:01 AM 1.22 0.00 02:00:01 AM 1.87 3.22 02:10:01 AM 12.91 0.06
Existen varias opciones para mostrar la memoria con sar, otra de ellas es con -r que genera un reporte con estadisticas del uso de memoria y swap.
[oracle@m9 ~]$ sar -r Linux 2.6.27.25-78.2.56.fc9.x86_64 (m9) 07/06/2010 12:00:01 AM kbmemfree kbmemused %memused kbbuffers kbcached kbswpfree kbswpused %swpused kbswpcad 12:10:01 AM 34860 4029104 99.14 32620 1324864 10026080 215256 2.10 10328 12:20:01 AM 40468 4023496 99.00 34092 1324428 10026460 214876 2.10 10292 12:30:01 AM 53092 4010872 98.69 37300 1301612 10026096 215240 2.10 10520 12:40:01 AM 57340 4006624 98.59 40412 1298040 10026004 215332 2.10 10580 12:50:01 AM 53336 4010628 98.69 42880 1299500 10025988 215348 2.10 10564 01:00:01 AM 84828 3979136 97.91 43588 1263016 10026028 215308 2.10 10224 01:10:01 AM 237544 3826420 94.15 13268 1156804 10017812 223524 2.18 10268
Para monitorear el espacio de un servidor linux, existen dos comandos muy útiles.
El primero es df(disk free), les recomiendo usarlo con la opción -h (human-readable) que automaticamente se ajusta al tamaño de cada filesystem mostrandolo en K, M, G o T.
[oracle@m9 ~]$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VolGroup00-LogVol00
137G 63G 68G 48% /
/dev/md0 99M 28M 67M 30% /boot
tmpfs 2.0G 545M 1.5G 28% /dev/shm
/dev/mapper/vgR0-lvR0
50G 39G 7.9G 84% /data0
/dev/mapper/vgR10-backups
119G 93G 21G 83% /backups
/dev/mapper/vgR0-oracle11g
99G 20G 75G 21% /u01
El segundo es du (disk usage), este nos muestra que directorios están utilizando el mayor espacio (recomendable usar -h). Por ejemplo para ver que esta consumiendo el mayor espacio en /u01 ejecutamos:
[oracle@m9 ~]$ du -h /u01 132K /u01/software/Disk1/stage/Actions/ntw32FoldersActions/10.2.0.3.0/1 136K /u01/software/Disk1/stage/Actions/ntw32FoldersActions/10.2.0.3.0 140K /u01/software/Disk1/stage/Actions/ntw32FoldersActions 24K /u01/software/Disk1/stage/Actions/ntCrsActionLib/10.2.0.1.0/1 28K /u01/software/Disk1/stage/Actions/ntCrsActionLib/10.2.0.1.0 32K /u01/software/Disk1/stage/Actions/ntCrsActionLib
Algunas variantes que podemos usar son: -s Para mostrar todo el espacio utilizado por este directorio y subdirectorios
[oracle@m9 db_1]$ du -sh /u01 20G /u01
Desplegar los 5 directorios que ocupan mayor espacio en /u01
[oracle@m9 u01]$ du -s /u01/* |sort -nr| head -5 16856112 /u01/app 3255624 /u01/software
En este caso solo contiene 2 directorios Monitoreando el I/O El comando iostat nos puede ayudar a determinar si tenemos un problema de I/O. La opción -x (extended) y -d (device) son muy útiles para generar el reporte. El siguiente ejemplo ejecuta el comando cada 10 segundos.
[oracle@m9 u01]$ iostat -xd 10 Linux 2.6.27.25-78.2.56.fc9.x86_64 (m9) 07/06/2010 Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util sda 0.22 7.90 0.52 4.87 25.47 106.80 24.57 0.04 6.80 2.55 1.37 sda1 0.00 0.00 0.00 0.00 0.00 0.00 8.71 0.00 11.35 10.77 0.00 sda2 0.10 0.22 0.04 0.05 1.17 2.27 36.37 0.00 8.69 5.74 0.05 sda3 0.11 7.68 0.48 4.81 24.30 104.53 24.36 0.04 6.77 2.51 1.33 sdb 0.22 7.93 0.52 4.84 25.82 106.80 24.75 0.03 6.19 2.93 1.57 dm-6 0.00 0.00 0.01 0.00 0.09 0.00 11.93 0.00 3.92 2.79 0.00 dm-7 0.00 0.00 0.01 0.00 0.07 0.00 8.00 0.00 2.16 1.80 0.00 dm-8 0.00 0.00 0.03 0.67 0.25 5.38 8.00 0.01 8.35 0.19 0.01
La forma de revisar este reporte es ver el %util que no este al 100% ya que esto indicaría un problema con el I/O. Si alguno de los discos que presenta alto consumo pertenece a oracle, entonces podemos ejecutar un query sobre la base de datos para determinar que session esta generando demasiadas escritura o lecturas.
SELECT * FROM (SELECT parsing_schema_name ,direct_writes ,SUBSTR(sql_text,1,75) ,disk_reads FROM v$sql ORDER BY disk_reads DESC) WHERE rownum < 20;
Este otro query es útil para determinar que objetos producen la mayoria de los I/O en la base de datos.
SELECT *
FROM
(SELECT
s.statistic_name
,s.owner
,s.object_type
,s.object_name
,s.value
FROM v$segment_statistics s
WHERE s.statistic_name IN
('physical reads', 'physical writes', 'logical reads',
'physical reads direct', 'physical writes direct')
ORDER BY s.value DESC)
WHERE rownum < 20;Una nota importante cuando monitoreamos el I/O, es que si estamos sobre una SAN (discos virtuales) la salida de iostat es a nivel del disco virtual, no de los discos fisicamente, esto puede dificultar encontrar que disco esta generando el cuello de botella, en estos casos debemos de trabajar con el administrador de la SAN para determinar que LUN es el del problema. Un comando que nos puede ayudar a realizar una prueba sobre nuestro filesystem es tomar el tiempo en que tarda en generar algunos archivos grandes y compararlos con otro ambiente que tenga un arreglo similar o configuración similar.
[oracle@m9 orc11g]$ time dd if=example01.dbf of=borrame.dbf 204816+0 records in 204816+0 records out 104865792 bytes (105 MB) copied, 2.4027 s, 43.6 MB/s real 0m2.441s user 0m0.074s sys 0m2.050s
Ya hemos comentado el comando sar con anterioridad y bueno este mismo nos puede dar también información del I/O con la opción -d.
[oracle@m9 orc11g]$ sar -d -f /var/log/sa/sa01 08:40:01 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util 08:50:01 AM dev8-0 3.95 2.80 79.00 20.68 0.02 4.30 2.73 1.08 08:50:01 AM dev8-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 08:50:01 AM dev8-2 0.01 0.17 0.00 17.33 0.00 19.33 14.00 0.01 08:50:01 AM dev8-3 3.94 2.63 79.00 20.69 0.02 4.26 2.71 1.07 08:50:01 AM dev8-16 3.93 4.16 79.00 21.15 0.02 4.68 3.14 1.24 08:50:01 AM dev8-17 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 08:50:01 AM dev8-18 0.01 0.15 0.00 22.00 0.00 9.50 7.75 0.01 08:50:01 AM dev8-19 3.92 4.01 79.00 21.15 0.02 4.67 3.13 1.23
Y para mostrar información actual cada 2 segundos para un total de 10 reportes.
[oracle@m9 orc11g]$ sar -d 2 10
Monitoreando el trafico Si llegamos a sospechar, que el problema de desempeño del servidor se debe a un problema en la red, podemos hacer uso del comando netstat con la opción – ptcn, el cuál despliega el ID del proceso, las conecciones TCP y se mantiene actualizando la salida.
[oracle@m9 orc11g]$ netstat -ptcn (Not all processes could be identified, non-owned process info will not be shown, you would have to be root to see it all.) Active Internet connections (w/o servers) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 127.0.0.1:42453 127.0.0.1:1522 ESTABLISHED 24028/java tcp 0 0 127.0.0.1:1522 127.0.0.1:59825 ESTABLISHED 30426/oracleorc11g tcp 0 0 192.168.1.4:19526 192.168.1.5:389 ESTABLISHED - tcp 0 0 127.0.0.1:59825 127.0.0.1:1522 ESTABLISHED 24028/java tcp 0 0 127.0.0.1:54088 127.0.0.1:1522 ESTABLISHED 24028/java tcp 0 0 192.168.1.4:36415 192.168.1.253:5053 ESTABLISHED - tcp 0 0 127.0.0.1:1522 127.0.0.1:37731 ESTABLISHED 3550/oracleorc11g tcp 0 0 127.0.0.1:1522 127.0.0.1:42490 ESTABLISHED 29529/oracleorc11g
Si tenemos valores muy altos en Send-Q (bytes not acknowledged by remote host), puede indicar que la red esta sobrecargada. Lo bueno de esta salida, es que nos indica el programa que lo esta generando. Generalmente cuando se tienen problemas de desempeño en un servidor de base de datos, la red no es el problema pero es importante revisarla y no dejarlo pasar.
Por último, podemos usar el comando sar para ver el historial de comportamiento de red con la opción -n y alguno de los siguientes argumentos: DEV (network devices), EDEV (error count), SOCK (sockets), o FULL (all).
[oracle@m9 orc11g]$ sar -n DEV Linux 2.6.27.25-78.2.56.fc9.x86_64 (m9.dbanet.dbaremoto.com.mx) 07/06/2010 12:00:01 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s 12:10:01 AM lo 11.69 11.69 2.02 2.02 0.00 0.00 0.00 12:10:01 AM eth0 372.28 220.06 334.77 15.05 0.00 0.00 0.00 12:10:01 AM vboxnet0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 12:10:01 AM pan0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 12:20:01 AM lo 11.88 11.88 2.19 2.19 0.00 0.00 0.00
FUENTES: http://www.dbasupport.com.mx/index.php/red-hat/redhat-administracion/233-herramientas-de-monitoreo-en-linux?showall=1
http://www.rubenortiz.es/2008/05/13/apache-maxclients-y-mas/